-
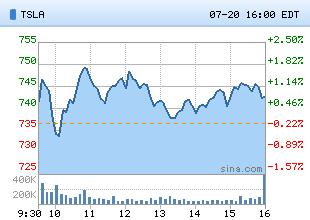
特斯拉第二季度营收169.34亿…
新浪科技讯北京时间7月21日凌晨消息,特斯拉汽车今天公布了该公司的2022财年第二季度财报。报告显示,特斯拉汽车第二季度营收为169.34亿… -
贵州数字经济增速连续6年全国第一
科技日报记者何星辉日前,在贵州省第十三届人民代表大会第五次会议上,贵州省省长李炳军在作政府工作报告时提到,2021年贵州数字经济加速突破,增…
人类怎样监督比自己聪明的AI?OpenAI首席科学家:可用弱AI监督强AI
- 发布时间:2023-09-16 点击次:703
-
人类怎样监督比自己聪明的AI?OpenAI首席科学家:可用弱AI监督强AI
AI大模型的安全问题越发成为业界关心的焦点问题。在OpenAI公司“宫斗”事件中,CEO山姆·奥尔特曼被认为是支持引进商业资本推动技术发展的“激进派”,而原首席科学家苏茨克维则是注重安全把关的“保守派”。
虽然在激烈内斗后,奥尔特曼上演“王者归来”,“激进派”占据了上风,但AI安全的问题也被摆上了台面。当地时间12月18日,OpenAI宣布了一套全新的监管框架,对奥尔特曼的权力进行制约。在这套框架下,一个新的安全团队将会定期向董事会汇报安全隐患,尽管奥尔特曼可以对此发表意见,但董事会也可以根据安全报告“一票否决”未来的大模型发布。
▲奥尔特曼
而在本月14日,由苏茨克维领导的“超级对齐”(Superalignment)团队刚刚发布成立以来的第一篇论文,为人类今后对AI模型的监管提供了思路:论文结论显示,用能力较弱的GPT-2来监督能力更强的GPT-4模型具有一定可行性。
苏茨维克一直认为,AI将在未来10年内发展到比人类更聪明的程度。“一个弱小的监管者怎样监督一个强大的AI”被视作今后AI领域必须面对的终极问题,有观点认为,“超级对齐”的研究让人类看到了一丝曙光。
OpenAI建新安全框架
董事会可以否决新模型发布
12月18日,OpenAI宣布采取一套新的“准备框架”用以规范今后的AI安全监管工作,这套框架已经处于测试阶段。领导新的安全框架的团队叫做“准备”(Preparedness)团队,是公司内部一个跨部门的职能团队,由麻省理工学院出身的计算机专家亚历山大·梅德里负责领导。
梅德里团队将针对各类AI模型进行能力评估和红线测试,以追踪、预测及防范各类别的灾难性风险。该团队每月会定期向一个新组建的内部安全咨询小组发送报告,该小组随后将对报告进行分析,并向奥尔特曼和董事会提交建议。奥尔特曼和其他公司高层可以根据这些报告决定是否发布新的AI模型,但董事会有权撤销奥尔特曼的决定。
▲苏茨克维(右)曾与奥尔特曼一起出席活动
在“宫斗”事件之后,奥尔特曼虽然回到OpenAI重新主持工作,但他的名字并不在“重启”后的董事会名单中。如今OpenAI在新模型发布这一重大问题上给予董事会“一票否决权”,被外界认为是制衡奥尔特曼个人权力的一项措施。
根据“准备”团队的工作手册,工作人员将反复评估OpenAI尚未发布的最先进AI模型,根据不同类型的风险类型评为四个等级,风险程度从低到高依次是“较低”“适中”“较高”和“严重威胁”。根据新的指导方针,OpenAI未来将只能推出风险评级为“较低”和“适中”的模型。手册显示,该团队最为关注的维度包括网络信息安全、模型是否教唆用户实施犯罪行动、是否泄露核机密或生化武器技术等。
此外,OpenAI还宣布了一项奖励计划,鼓励任何研究者、学校或科研机构就AI安全方面做出技术贡献,奖金最高可达1000万美元。而且OpenAI承诺如果有较好的研究方向,可以通过“快捷通道”向该公司申请资金支持。
苏茨维克团队论文:
GPT-2可以监督GPT-4
OpenAI官网介绍称,“超级对齐”团队于今年7月成立,由首席科学家苏茨克维领导,目标是在4年内解决“超级智能对齐”问题,即如何让AI系统发展的终极目标符合人类的价值观和利益。为此OpenAI拨出全公司20%的计算能力供“超级对齐”团队调配。
▲“超级对齐”团队用插画说明“让AI对齐AI”的思路
对于这个安全方面的终极问题,在今年8月时苏茨克维对外界讲述了自己的思路,就是让“AI对齐AI”。这个思路可以用该团队论文中的一幅插图形象地展现出来:在早期阶段人类比AI强,监督AI的学习并不成问题,但在未来的某个阶段AI的能力会超过人类,届时如何监督更强大的AI?而解题思路是,让前一代能力较弱的AI模型去监督下一代更强的AI模型,然后以此类推。
这篇论文借鉴了人类如何监督早期GPT模型的思路,试着让GPT-2去监督GPT-4的学习。结论认为,虽然目前GPT-2还没有办法“批量化复制”人类的监督工作思路,但在能力较弱的GPT-2的监督下,GPT-4还是达到了大部分的潜能。
具体来说,如果完全依靠GPT-2来监督新模型的训练和学习,那么新模型所能达到的水平大约介于GPT-3和GPT-3.5之间。但是如果加上少量的人工监督,模型就能做到现在GPT-4能做的绝大部分事情。
这篇论文的主要合著者之一简·雷克总结表示,研究证明未来的AI模型可以在完全脱离人类监督的情况下变得比弱小监管者(即上一代旧模型)更加聪明。尽管这种进步幅度不算太大,也有很多条件限制,但无论如何这为人类在未来放心“让AI自己去对齐AI”打造了一个良好的开端。
红星新闻记者 郑直
编辑 郭宇 责编 李彬彬